目次
変分オートエンコーダ(VAE)とは?基本を理解しよう
変分オートエンコーダ(Variational Autoencoder、VAE)は、データの特徴を学習し、新しいデータを生成できるAI技術です。製造業の異常検知や医療画像の分析、デザイン案の生成など、幅広い分野で活用が進んでいます。
変分オートエンコーダの定義と役割
変分オートエンコーダとは、データを圧縮・復元する過程で本質的な特徴を学習し、新しいデータを生成できる生成モデルです。
例えば、製品画像を学習させることで、実在しないが「それらしい」新しいデザインを生成できます。正常な機械の動作データを学習させれば、異常な動作を検知することも可能です。
VAEの主な役割は3つです:
- データ生成:学習データに似た新しいデータを作り出す
- 異常検知:正常データとの差異から異常を発見する
- 特徴抽出:データの本質的な特徴を自動的に見つける
従来のデータ処理では、人間が重要な特徴を事前に決める必要がありました。VAEはデータから自動的に特徴を学習するため、人間が気づかなかったパターンを発見することもあります。
通常のオートエンコーダとの違い
VAEを理解するには、まず「オートエンコーダ(AE)」を知る必要があります。
通常のオートエンコーダは、データを圧縮してから復元することで重要な特徴を学習します。高画質写真をZIP形式で圧縮・解凍するイメージです。
変分オートエンコーダは、圧縮時に「確率分布」を取り入れています。これにより以下の違いが生まれます:
| 項目 | オートエンコーダ(AE) | 変分オートエンコーダ(VAE) |
|---|---|---|
| 圧縮方法 | 固定された一点に変換 | 確率分布として表現 |
| 新規データ生成 | 苦手 | 得意 |
| データの多様性 | 限定的 | 豊富なバリエーション |
| 主な用途 | 圧縮、特徴抽出 | データ生成、異常検知 |
通常のAEは「りんごの写真」を再現できますが、新しいりんご画像の生成は苦手です。VAEは学習データにない新しいりんごを、色や形を変えて生成できます。
この違いは、VAEが「データの特徴を幅を持たせて学習する」ことから生まれます。一点ではなく範囲として特徴を捉えるため、その範囲内で新しいデータを生成できるのです。
VAEが得意とすること・苦手とすること
得意とすること
- 新しいデータの生成:学習データに似た新規データを作成
- データの補間:2つのデータの中間を自然に生成
- 異常検知:正常データから外れたものを検知
- 少ないデータでの学習:数百〜数千のサンプルで実用可能
- 安定した学習:他の生成モデルより学習が安定
苦手とすること
- 細部の精度:生成画像がやや「ぼやけた」印象になる
- 複雑なデータ:非常に詳細なデータの生成は困難
- 学習範囲外:学習していない種類のデータは生成不可
これらの特性を理解し、自社の課題に適しているか判断することが重要です。高精細な画像生成が必要ならGANなど他の技術を、安定したデータ生成や異常検知が目的ならVAEが適しています。
変分オートエンコーダの仕組み
VAEの動作原理を、数式を使わず概念的に解説します。
エンコーダとデコーダの役割
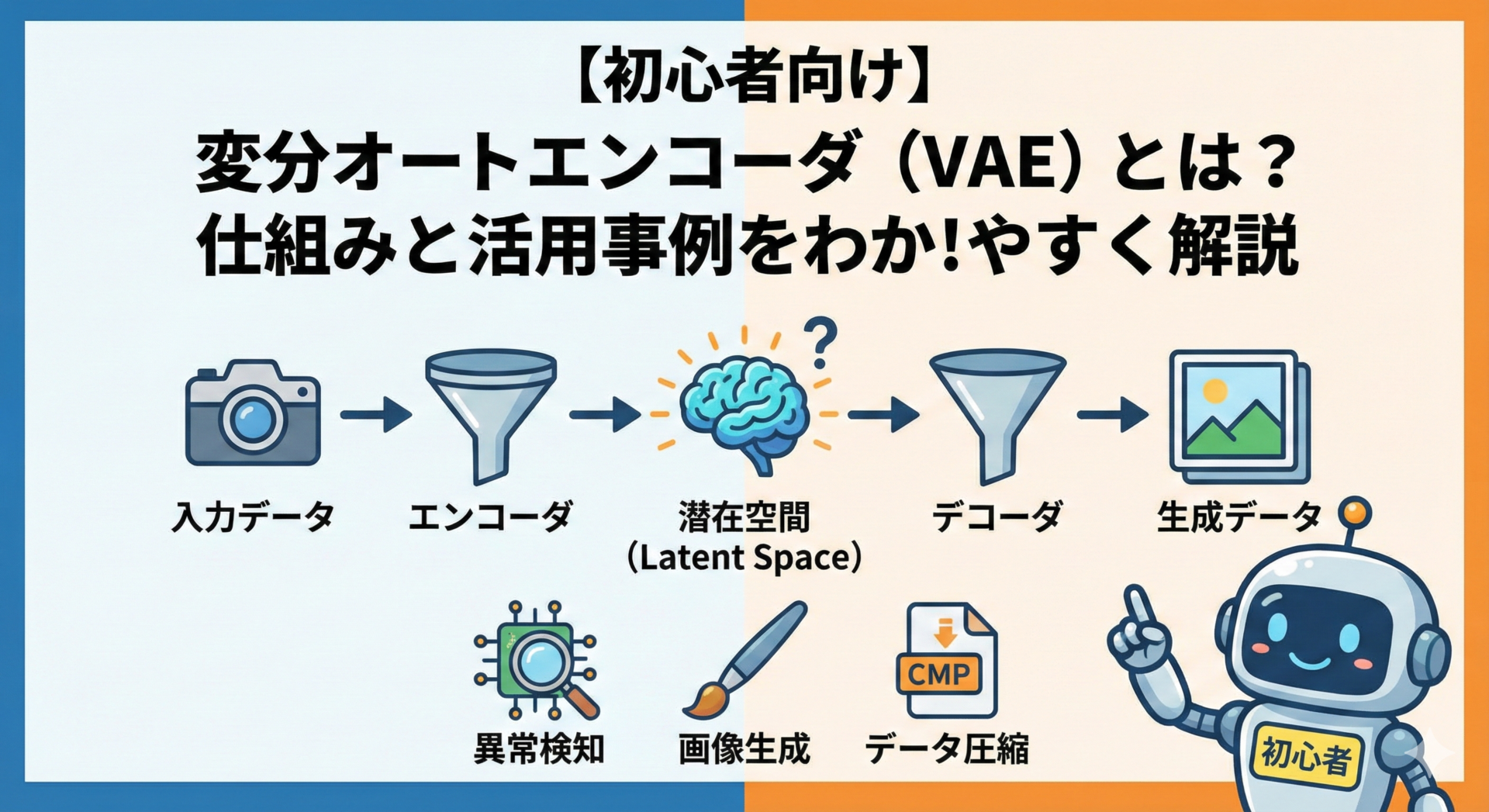
VAEは**エンコーダ(Encoder)とデコーダ(Decoder)**の2つから構成されます。
エンコーダ:データを圧縮する
入力データの特徴を抽出して圧縮します。犬の写真なら「耳の形」「毛の色」「体の大きさ」を数値化し、コンパクトな情報に変換します。この圧縮情報を潜在変数と呼びます。
デコーダ:データを復元・生成する
潜在変数を受け取り、元のデータに近い形に復元します。重要なのは、完全に同じものではなく「それらしい」データを生成する点です。これにより新しいデータを作り出せます。
連携の流れ
- エンコーダがデータを圧縮
- 潜在変数として保存
- デコーダが潜在変数から復元
- 元データと復元データの差を計算
- 差が小さくなるよう学習を繰り返す
この繰り返しで、VAEはデータの本質的特徴を学習します。
潜在空間と確率分布
潜在空間とは
データの本質的特徴だけを抽出した抽象的な空間です。顔写真を学習させたVAEでは、「年齢」「性別」「表情」「髪型」が数値の組み合わせで表現されます。
潜在空間の特徴:
- 次元削減:数千〜数万の次元が数十〜数百に圧縮
- 意味のある配置:似た特徴のデータは近くに配置
- 連続性:任意の点から意味のあるデータを生成可能
確率分布を使う理由
通常のAEは各データを潜在空間の「一点」に対応させます。これでは学習データの再現は得意でも、新しいデータの生成が苦手です。
VAEは各データを確率分布として表現します。「りんごの写真」を特定の一点ではなく「ある範囲」に対応させることで:
- 多様なデータ生成が可能
- 潜在空間に隙間がなくなる
- ノイズに対して安定
- 自然な補間が可能
VAEは通常「正規分布」を使い、「平均」と「分散」でデータを表現します。この確率分布からランダムにサンプリングすることが、新しいデータを生成する能力の源です。
学習の流れ
- データ入力:学習用データをVAEに入力
- エンコード:潜在変数の確率分布を出力し、ランダムにサンプリング
- デコード:サンプリングした潜在変数から復元
- 誤差計算:元データと復元データの差を評価
- パラメータ更新:誤差をもとに調整
- 繰り返し:何千回、何万回と繰り返して性能向上
学習後は、潜在空間からランダムに点を選んでデコードすることで新規データを生成したり、既存データの潜在変数を操作してデータ変換したりできます。
他の技術との比較
GAN(敵対的生成ネットワーク)との違い
VAEと並んで有名な生成モデルにGANがあります。GANは「生成器」と「識別器」を競わせて学習する手法です。
| 比較項目 | VAE | GAN |
|---|---|---|
| 生成品質 | やや低い(ぼやけがち) | 高い(鮮明) |
| 学習の安定性 | 安定 | 不安定 |
| 必要データ量 | 少ない(数百〜) | 多い(数千〜数万) |
| 学習時間 | 比較的短い | 長い |
| 潜在空間 | 明確で操作しやすい | 解釈が難しい |
| 異常検知 | 得意 | やや不得意 |
| 実装難易度 | 中程度 | 高い |
選択基準
- データ量が限られている → VAE
- 安定した運用が重要 → VAE
- 異常検知が目的 → VAE
- 高品質な画像生成が必須 → GAN
中小企業では、まずVAEから始めて必要に応じてGANを検討するアプローチが現実的です。
使い分けのポイント
| 業務シーン | 推奨技術 | 理由 |
|---|---|---|
| 製造業の異常検知 | VAE | 安定した学習、少データでも可能 |
| 品質管理の自動化 | VAE | 正常データからの逸脱を検知しやすい |
| デザイン案の生成 | VAE→GAN | まずVAEで試し、品質が必要ならGAN |
| データ拡張 | VAE | 多様なバリエーション生成に適す |
| 画像のノイズ除去 | AE | シンプルで効果的 |
変分オートエンコーダの活用事例
製造業での異常検知・品質管理
活用例1:製品外観検査の自動化
正常品の画像を学習させたVAEで、不良品を自動検出します。従来は熟練検査員が目視で行っていた作業を、24時間365日安定して実行できます。
- 検査時間:1個あたり数秒
- 検出精度:95%以上
- 導入効果:検査コスト60%削減
活用例2:設備の予知保全
機械の振動データや温度データを学習し、異常の予兆を検知します。突発的な故障を防ぎ、計画的なメンテナンスが可能になります。
画像生成・データ拡張
活用例3:学習データの拡張
少ない画像データから多様なバリエーションを生成し、機械学習モデルの精度を向上させます。特に希少なデータ(不良品画像など)の収集が困難な場合に有効です。
活用例4:デザイン案の生成
既存製品のデザインを学習し、新しいデザイン案を自動生成します。デザイナーのアイデア出しを支援し、創造性を補完します。
中小企業でも取り組める活用シーン
小規模から始められる事例
- 書類の異常検知:請求書や発注書のフォーマット崩れを検出
- 在庫写真の管理:類似商品の自動分類
- 顧客データの分析:購買パターンの可視化
- 作業動画の分析:標準作業からの逸脱を検知
これらは数万円〜数十万円の初期投資で始められ、段階的に拡大できます。
学習の始め方
必要な前提知識
必須の基礎知識(学習期間:1〜2ヶ月)
- Pythonプログラミングの基本:変数、関数、クラスの概念
- 機械学習の基礎:教師あり・なし学習の違い、損失関数の考え方
- ニューラルネットワークの基本:層、ノード、重みの概念
完璧な理解は不要です。概要を掴んだら実践しながら学ぶスタイルが効果的です。
実践的な学習方法
ステップ1:環境構築(1〜2時間)
Google Colabを使えば、ブラウザだけで即座に始められます。ソフトウェアのインストール不要で、無料のGPUも利用可能です。
ステップ2:サンプルコード実行(2〜3時間)
GitHubから簡単なVAE実装を取得し、実行します。パラメータを変えて挙動を観察することで理解が深まります。
おすすめ練習プロジェクト
- 初級:MNISTデータセット(手書き数字)でのVAE実装
- 中級:自社の製品画像での異常検知システム
- 上級:条件付きVAE(CVAE)の実装
効果的な学習サイクル
週2〜3回、以下のサイクルを繰り返します:
- 理論を学ぶ(30分)
- コードを写経する(1時間)
- パラメータを変えて実験(1時間)
- 結果を分析(30分)
よくあるつまずきポイント
問題1:数式が難しい
→ まず実装から始め、動くコードを見ながら後から理解する
問題2:学習が収束しない
→ 学習率を小さくする、バッチサイズを調整する
問題3:生成画像がぼやける
→ VAEの特性として受け入れる、必要なら他手法も検討
問題4:実務への適用が分からない
→ 小規模データで実験、外部専門家に相談
中小企業での導入ポイント
自社に合った技術か見極める
適合性チェックリスト
□ データの異常や品質のばらつきを検知したい
□ 限られたデータから新しいサンプルを生成したい
□ 画像や時系列データを扱っている
□ 人手による検査作業がある
□ 既存のルールベース判定に限界を感じている
「はい」が多いほど、VAE導入の価値が高いと言えます。
導入すべきでないケース
- データがほとんどない(数十件以下)
- 単純な統計処理で解決できる
- 技術を維持できる人材がいない
- 投資対効果が明らかに低い
スモールスタートで始める
段階的な導入ステップ
Phase 1:概念実証(1〜2ヶ月、10〜30万円)
小規模データで実験し、技術的実現可能性を検証
Phase 2:パイロット導入(2〜3ヶ月、30〜100万円)
特定部署に限定して導入し、効果を定量測定
Phase 3:本格展開(6ヶ月〜)
全社展開と継続的改善
小さく始めることで、リスクを最小化しながら知見を蓄積できます。
内製化か外部委託か
推奨アプローチ:ハイブリッド型
- 初期開発:外部パートナーに委託
- 知識移転:開発過程で社内メンバーも参加
- 運用・改善:基本的な調整は内製化
- 高度な改修:必要に応じて外部に相談
このアプローチなら、スピードとノウハウ蓄積を両立できます。
外部パートナー選びのポイント
□ 中小企業への導入実績がある
□ 技術だけでなく業務理解がある
□ 導入後のサポート体制が明確
□ 段階的な導入に対応してくれる
□ 技術移転に協力的
運用体制づくり
必要な3要素
- 技術担当者:基本的な仕組みを理解し、簡単な調整ができる人材(最低1名)
- データ管理:定期的な更新、品質チェック、バックアップの仕組み
- 効果測定:月次または四半期ごとのレビューと改善サイクル
運用コストの目安(年間)
- 人件費:担当者の工数(月5〜20時間)
- サーバー費用:月1〜5万円
- 保守サポート:20〜100万円
- 再学習・改善:30〜150万円
合計で年間50〜300万円程度が一般的です。
まとめ
変分オートエンコーダの本質
VAEは、データの特徴を確率分布として学習し、新しいデータを生成できる技術です。エンコーダとデコーダの2つの部分で構成され、潜在空間を使ってデータの本質を捉えます。
主な活用シーン
- 異常検知:製造業の品質管理、設備の予知保全
- データ生成:学習データの拡張、デザイン案の作成
- 特徴抽出:データ分析の前処理、可視化
導入のポイント
- 自社の課題とVAEの相性を見極める
- スモールスタートで段階的に進める
- 内製と外部委託をバランスよく組み合わせる
- 導入後の運用体制を事前に整える
次のアクション
すぐに始められること
- Google Colabで簡単なVAEコードを動かしてみる
- 自社のデータでVAEが活用できそうか検討する
- 社内で小さな勉強会を開催する
困ったときは専門家に相談を
VAEの導入や活用でお困りの際は、Harmonic Societyにご相談ください。中小企業に寄り添った「ちょうどいいデジタル化」を、AI活用により従来の1/5の費用、1/10の期間で実現します。
概念実証から本格導入、運用サポートまで一気通貫で伴走支援いたします。まずはお気軽にお問い合わせください。