目次
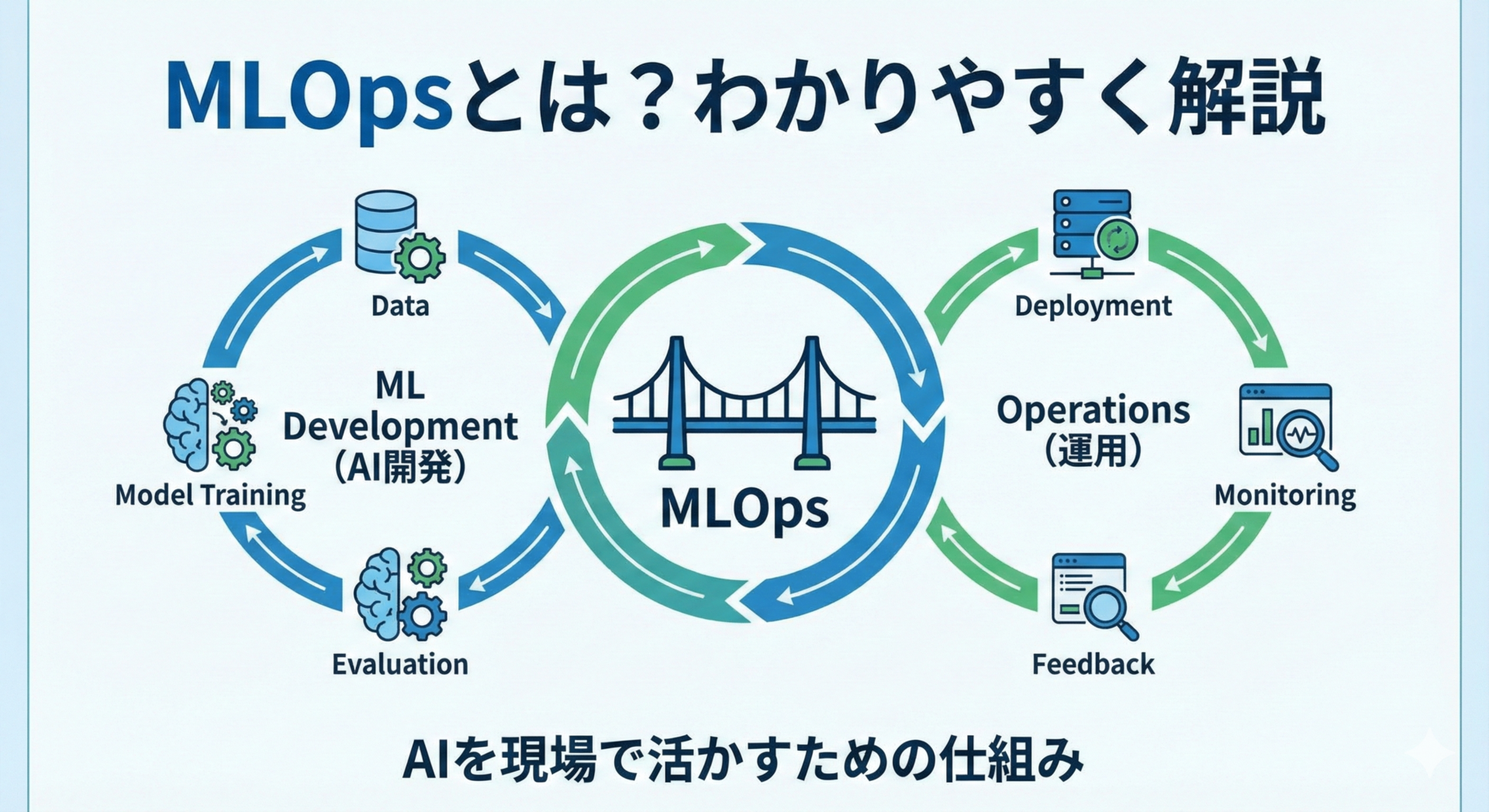
MLOpsとは?AIを現場で活かし続けるための仕組み
「AIを導入したけれど、うまく運用できていない」「せっかく作った機械学習モデルが現場で使われなくなってしまった」——このような課題に直面していませんか?
実は、開発したモデルをビジネスで継続的に活用できている企業は少数です。その理由は、開発と運用の間に大きなギャップがあるからです。
この課題を解決する仕組みが「MLOps」です。本記事では、MLOpsの基本的な考え方から実践的なメリット、中小企業での取り組み方まで、わかりやすく解説します。
MLOpsとは?基本を押さえよう
**MLOps(エムエルオプス)**とは、Machine Learning(機械学習)とOperations(運用)を組み合わせた造語で、AIモデルを開発するだけでなく、実際のビジネス現場で継続的に動かし続けるための仕組みや考え方を指します。
多くの企業では、データサイエンティストが優れた機械学習モデルを開発しても、本番環境で安定的に運用することに苦労しています。開発環境では高い精度を示していたモデルが、実際の業務では期待通りの結果が出ない、あるいは時間が経つにつれて精度が落ちてしまう——こうした問題は決して珍しくありません。
MLOpsは、こうした開発と運用のギャップを埋めるための実践的なアプローチです。単なる技術的な手法ではなく、組織やプロセス全体を含めた包括的な取り組みといえます。
なぜ今、MLOpsが注目されているのか
MLOpsが注目されている背景には、AIの実用化が進むにつれて、運用面の課題が顕在化してきたことがあります。
数年前まで、機械学習は研究開発や実験的なプロジェクトで使われることが主流でした。しかし現在では、需要予測、異常検知、チャットボット、画像認識など、さまざまな業務でAIが実際に活用されるようになっています。
ところが、AIを本番環境で動かし続けることは想像以上に困難です。以下のような課題が次々と浮上してきました。
- データの変化:ビジネス環境や顧客の行動が変われば、学習時のデータと実際のデータに差が生じる
- モデルの劣化:時間の経過とともに予測精度が低下してしまう
- 属人化:特定の担当者しかモデルの仕組みを理解しておらず、引き継ぎが困難
- スピード不足:モデルの改善や再学習に時間がかかり、ビジネスの変化に追いつけない
こうした課題を解決し、AIを継続的にビジネス価値につなげるために、MLOpsの重要性が高まっているのです。
開発と運用のギャップとは
機械学習プロジェクトにおける最大の課題の一つが、開発環境と本番環境の違いです。
開発フェーズでは、データサイエンティストが過去のデータを使ってモデルを訓練し、高い精度を達成します。しかし、それを実際の業務システムに組み込んで運用しようとすると、さまざまな問題が発生します。
主なギャップ:
- データの性質:開発では整理された過去データを使うが、本番では欠損や異常値を含むリアルタイムデータを扱う
- 処理速度の要求:開発では数時間かけて学習しても問題ないが、本番では数秒以内に予測結果を返す必要がある
- 責任の所在:開発はデータサイエンティストが担当するが、運用はインフラエンジニアやシステム管理者が担当する
- 評価基準:開発では精度などの統計指標で評価するが、本番ではビジネス成果で評価される
このギャップを放置すると、せっかく開発した優れたモデルが現場で使われなくなるという事態に陥ります。MLOpsは、この開発と運用の間にある溝を埋め、機械学習モデルを確実にビジネス価値につなげる架け橋となる仕組みなのです。
DevOpsとの違いは何?
MLOpsを理解する上で、よく比較されるのが「DevOps」です。両者は似た考え方を持ちながらも、機械学習特有の要素によって重要な違いがあります。
DevOpsとは
DevOps(デブオプス)とは、開発(Development)と運用(Operations)の壁を取り払い、協力しながらソフトウェアを継続的に改善していく考え方や実践方法です。
DevOpsの主な要素:
- 継続的インテグレーション(CI):コードの変更を頻繁に統合し、自動テストで品質を保つ
- 継続的デリバリー(CD):テストに合格したコードを自動的に本番環境へデプロイできる状態にする
- 自動化:テスト、デプロイ、監視などを自動化し、人的ミスを減らす
- モニタリング:システムの状態を常に監視し、問題を早期発見する
DevOpsの導入により、リリースサイクルが短縮され、品質が向上し、チーム間の協力が促進されます。
MLOpsが異なる3つのポイント
MLOpsはDevOpsの考え方を機械学習に応用したものですが、AIシステムならではの特性により、いくつかの重要な違いがあります。
1. データが中心的な役割を果たす
通常のソフトウェアでは、コードが成果物の中心です。同じコードをデプロイすれば基本的に同じ動作をします。
一方、機械学習ではデータとコードの両方が成果物です。同じコードを使っても、学習に使うデータが変われば、まったく異なるモデルが出来上がります。そのため、MLOpsでは以下の管理が必要になります。
- データのバージョン管理:どのデータでモデルを学習したかを記録
- データの品質管理:欠損値、異常値、偏りなどをチェック
- データの変化の監視:本番環境のデータが学習時と異なっていないか確認
2. モデルの性能が時間とともに変化する
通常のソフトウェアは、一度デプロイすれば基本的に同じ動作を続けます。しかし、機械学習モデルは時間の経過とともに性能が劣化する可能性があります。
たとえば、顧客の購買行動を予測するモデルを考えてみましょう。学習時は2022年のデータを使っていたとします。しかし、2024年になると消費者の好みや経済状況が変わり、予測精度が落ちてしまうかもしれません。
このモデルの劣化(Model Decay)は、主に以下の理由で発生します。
データドリフト:学習時のデータと本番環境のデータの分布が変化してしまうこと。例えば、コロナ禍前のデータで学習したモデルは、コロナ禍後の消費行動の変化に対応できません。
コンセプトドリフト:入力と出力の関係性そのものが変化してしまうこと。例えば、不正検知システムでは、詐欺師が新しい手口を開発すると、従来のパターンでは検知できなくなります。
そのため、MLOpsでは以下の仕組みが重要になります。
- 性能のモニタリング:予測精度や誤差を継続的に監視
- 再学習のトリガー:精度が一定以下になったら自動的に再学習
- モデルのバージョン管理:複数のモデルを管理し、必要に応じてロールバック
3. 実験と反復が開発の中心
通常のソフトウェア開発では、要件が明確で、決まった機能を実装すれば完成です。
しかし、機械学習では「どのアルゴリズムが最適か」「どのパラメータが最良か」を事前に知ることはできません。そのため、多数の実験を繰り返し、最も良い結果を出すモデルを探すプロセスが必要です。
MLOpsでは、この実験プロセスを効率化するために以下の取り組みが行われます。
- 実験管理:試したパラメータと結果を記録し、比較できるようにする
- 再現性の確保:同じ条件で実験を再現できるように環境を管理
- 並列実験:複数の実験を同時に実行し、最適解を早く見つける
通常のソフトウェアなら「一度作れば動き続ける」ことが期待されますが、機械学習では「継続的なメンテナンスが前提」という認識が重要です。
MLOpsのメリット
実際にMLOpsを導入すると、具体的にどのようなメリットがあるのでしょうか。特に中小企業にとって現実的なメリットを中心に解説します。
開発スピードと改善サイクルの向上
MLOpsの最大のメリットの一つが、機械学習モデルの開発から本番適用までのスピードが劇的に向上することです。
従来の機械学習プロジェクトでは、モデルを開発してから本番環境にデプロイするまでに、数週間から数ヶ月かかることも珍しくありませんでした。その間に、環境構築、テスト、セキュリティチェック、ドキュメント作成など、多くの手作業が必要だったからです。
MLOpsでは、これらのプロセスを自動化・標準化することで、以下のような改善が実現します。
CI/CDによる自動化
- コードの変更をプッシュすると、自動的にテストが実行される
- テストに合格したモデルは、ボタン一つで本番環境にデプロイできる
- 手作業によるミスや遅延が大幅に削減される
実験サイクルの高速化
- 複数のモデルを並行して試すことができる
- 結果を自動的に記録・比較できるため、最適なモデルを素早く見つけられる
たとえば、需要予測モデルの精度を改善したいとき、従来なら「新しいアルゴリズムを試す→結果を確認→本番反映」に1ヶ月かかっていたとします。MLOpsを導入すれば、同じプロセスを数日、場合によっては数時間で完了できるようになります。
属人化の防止とチーム運用の実現
中小企業が機械学習を導入する際の大きな課題の一つが、特定の技術者に依存してしまう属人化です。
MLOpsは、この属人化を解消し、チーム全体で機械学習システムを運用できる体制を作ります。
ドキュメント化と標準化
MLOpsでは、以下の情報を体系的に記録・管理します。
- どのデータを使ってモデルを学習したか
- どのパラメータやアルゴリズムを使ったか
- モデルの性能はどうだったか
- なぜそのモデルを本番採用したか
これらの情報が整理されていれば、担当者が変わっても、過去の経緯を理解し、適切な判断ができます。
再現可能な環境
MLOpsでは、開発環境や実験の条件を記録し、いつでも再現できるようにします。「あのとき、どうやって作ったモデルだったか思い出せない」という事態を防げます。
明確な役割分担
- データサイエンティスト:モデルの開発と改善に集中
- エンジニア:インフラとデプロイの自動化を担当
- ビジネス担当者:モデルの性能をビジネス指標で評価
それぞれが自分の専門分野に集中でき、かつ連携しやすい環境が整います。
モデル品質の安定化
機械学習モデルは「作って終わり」ではなく、継続的に品質を監視し、維持する必要があります。MLOpsは、この品質管理を体系的に行う仕組みを提供します。
リアルタイムのモニタリング
- 予測精度の追跡:実際の結果と予測を比較し、精度を測定
- データの変化の検知:入力データの分布が学習時と異なっていないかチェック
- 異常の早期発見:予測結果に異常なパターンがないか監視
これにより、モデルの劣化を早期に発見し、ビジネスへの悪影響を最小限に抑えることができます。
自動的な再学習とロールバック
性能の低下が検知されたら、以下のような対応を自動的に行うことができます。
- 最新のデータでモデルを再学習
- 新しいモデルをテスト環境で検証
- 問題なければ本番環境に自動デプロイ
- 問題があれば以前のバージョンにロールバック
コストと工数の削減
「MLOpsを導入するには、かえってコストがかかるのでは?」と心配される方もいるかもしれません。しかし、中長期的に見ると、MLOpsは大幅なコスト削減と工数の効率化をもたらします。
手作業の削減
従来、手動で行っていた以下のような作業を自動化することで、技術者がより価値の高い業務に時間を使えるようになります。
- モデルの学習環境のセットアップ
- 学習結果の記録と比較
- 本番環境へのデプロイ作業
- 性能の定期的なチェック
インフラコストの最適化
MLOpsでは、必要なときだけ計算リソースを使う仕組みを作りやすくなります。
- 学習時だけクラウドの強力なGPUを使用
- 推論時は軽量な環境で動作
- 使っていないリソースは自動的にシャットダウン
トラブル対応の迅速化
モデルに問題が発生したとき、MLOpsの仕組みがあれば原因を素早く特定できます。これらの情報がすぐに分かるため、トラブルシューティングにかかる時間が大幅に短縮されます。
初期投資は必要ですが、MLOpsは長期的なROI(投資対効果)が非常に高い取り組みです。
MLOpsの構成要素と流れ
実際にMLOpsはどのような要素で構成され、どのような流れで機能するのでしょうか。ここでは、MLOpsのライフサイクル全体像と、各フェーズで行うことを解説します。
データ管理とバージョン管理
機械学習において、データは最も重要な資産です。MLOpsの第一歩は、このデータを適切に管理することから始まります。
データのバージョン管理
ソフトウェア開発でGitを使ってコードのバージョンを管理するように、機械学習でもデータのバージョンを管理する必要があります。
データバージョン管理では、以下の情報を記録します。
- データの取得日時
- データのソース(どこから取得したか)
- データの前処理内容
- データのサイズや統計情報
データの品質管理
機械学習では「Garbage In, Garbage Out(ゴミを入れればゴミが出る)」という言葉があります。質の悪いデータで学習すれば、質の悪いモデルしかできません。
そのため、以下のようなチェックを自動化します。
- 欠損値の検出:データに抜けがないか
- 異常値の検出:常識的にありえない値が含まれていないか
- データの偏りの確認:特定のカテゴリに偏っていないか
- スキーマの検証:データの形式が期待通りか
モデルの学習・評価・デプロイ
データの準備ができたら、次はモデルの開発と本番環境への適用です。
実験管理(Experiment Tracking)
機械学習では、最適なモデルを見つけるために多数の実験を行います。MLOpsでは、これらの実験を体系的に管理します。
記録する情報の例:
- 使用したアルゴリズム
- ハイパーパラメータ
- 使用したデータのバージョン
- 学習にかかった時間
- 評価指標(精度、再現率、F値など)
モデルのバージョン管理
データと同様、モデル自体もバージョン管理が必要です。これにより、**問題が起きたときに以前のバージョンに戻す(ロールバック)**ことが簡単にできます。
自動デプロイとCI/CD
テストに合格したモデルを、人手を介さずに本番環境にデプロイする仕組みを作ります。
典型的なCI/CDパイプラインの流れ:
- データサイエンティストが新しいモデルを開発
- コードをリポジトリにプッシュ
- 自動的にテストが実行される
- テストに合格したら、ステージング環境にデプロイ
- ステージング環境で問題なければ、本番環境にデプロイ
モニタリングと再学習の自動化
本番環境にデプロイしたモデルは、継続的に監視し、必要に応じて更新する必要があります。
性能監視
- 予測精度の推移をリアルタイムで追跡
- データドリフトの検知
- 異常な予測結果の検出
自動再学習
性能が低下したら、自動的に以下のプロセスを実行します。
- 最新のデータを収集
- モデルを再学習
- テスト環境で検証
- 本番環境にデプロイ
ガバナンスとセキュリティ
企業でAIを活用する上で、ガバナンスとセキュリティは欠かせません。
モデルのガバナンス
- 誰がいつ、どのモデルをデプロイしたかの記録
- モデルの承認プロセスの管理
- 規制やコンプライアンスへの対応
セキュリティ
- データへのアクセス制御
- モデルの不正利用の防止
- プライバシー保護(個人情報の適切な取り扱い)
代表的なMLOpsツール
「実際にどんなツールを使えばいいの?」という疑問が浮かぶかもしれません。
ここでは代表的なMLOpsツールを紹介しますが、最初にお伝えしたいのは「ツールありき」で考える必要はないということです。大切なのは、自社の課題を解決できるか、現場で無理なく使い続けられるかという視点です。
クラウドサービス
大手クラウドプロバイダーは、MLOpsに必要な機能を統合したサービスを提供しています。
AWS(Amazon Web Services)
- Amazon SageMaker:モデルの開発からデプロイまでを一貫してサポート
- AWSの他のサービスと連携しやすい
Azure(Microsoft)
- Azure Machine Learning:GUIが使いやすく、コードを書かなくても操作できる部分が多い
- Microsoft製品との連携が強み
GCP(Google Cloud Platform)
クラウドサービスのメリット
- インフラの構築・管理が不要
- スケーラビリティが高い
- セキュリティやバックアップも標準で提供
注意点
- 月額費用が発生する
- 特定のクラウドに依存すると、後で別のサービスに移行しにくい
オープンソースツール
無料で利用できるオープンソースのMLOpsツールも充実しています。
MLflow
- 実験管理に特化したツール
- シンプルで導入しやすく、小規模プロジェクトに最適
- Python環境があればすぐに使い始められる
Kubeflow
- Kubernetes上で動作する本格的なMLOpsプラットフォーム
- 大規模な機械学習システムに向いている
- ただし、Kubernetesの知識が必要で学習コストは高め
DVC(Data Version Control)
- データのバージョン管理に特化
- Gitのようにデータの変更履歴を追跡できる
オープンソースツールのメリット
- 基本的に無料で利用できる
- カスタマイズの自由度が高い
- 特定のベンダーに依存しない
注意点
- 自社でインフラを用意・管理する必要がある
- トラブル時のサポートは基本的に自己解決
ツール選びのポイント
MLOpsツールを選ぶ際は、以下のポイントを考慮しましょう。
- 現在の技術スタックとの相性:既存の環境にスムーズに組み込めるツールを選ぶ
- チームのスキルレベル:チームが無理なく使いこなせるレベルのツールを選ぶ
- 必要な機能の優先順位:最も課題になっている部分から着手する
- コストと予算:初期費用だけでなく、月額費用や運用コストも含めて検討
- サポート体制:トラブルが起きたときに頼れるサポートがあるか
「導入ありき」ではなく、段階的に
ツールを選ぶ前に、まずはExcelやスプレッドシートで実験記録を始めるのも立派な第一歩です。実際に運用してみて、「ここが不便」「この作業を自動化したい」という具体的な課題が見えてから、それを解決できるツールを導入する方が失敗は少なくなります。
中小企業がMLOpsに取り組む際のポイント
「理屈はわかったけど、うちの会社で本当にできるだろうか?」と不安に感じる方もいるかもしれません。
特に中小企業では、IT人材が限られている、予算に余裕がない、既存の業務で手一杯といった現実的な課題があります。
しかし、MLOpsは大企業だけのものではありません。むしろ、限られたリソースで最大の効果を出す必要がある中小企業こそ、MLOpsの考え方が役立ちます。
小さく始めることが大切
MLOpsと聞くと、「最初から完璧なシステムを構築しなければ」と考えてしまいがちです。しかし、いきなり完璧を目指す必要はまったくありません。
「できるところから、小さく始める」——これがMLOps導入の鉄則です。
ステップ1:実験記録から始める
最初の一歩として、まずは実験の記録を残すことから始めましょう。どんなデータを使ったか、どんなパラメータで学習したか、結果はどうだったか——これをExcelやスプレッドシートに記録するだけでも、大きな前進です。
ステップ2:一つのモデルだけ自動化する
次に、最も頻繁に使うモデルや、最も時間がかかっている作業を一つだけ自動化してみましょう。たとえば、毎月行っている需要予測モデルの再学習を自動化するだけでも、担当者の負担は大きく軽減されます。
ステップ3:成功体験を積み重ねる
小さな成功を積み重ねることで、チーム内に「MLOpsは役に立つ」という実感が生まれます。この実感こそが、次のステップに進む原動力になります。
自社の業務フローに合った仕組みづくり
MLOpsに「正解」はありません。教科書通りの仕組みが、必ずしも自社に合うとは限りません。
大切なのは、自社の業務フローや文化に合った「ちょうどいい仕組み」を作ることです。
現場の声を聞く
MLOpsの仕組みを作る際は、実際にAIを使う現場の担当者の声をしっかり聞きましょう。どこで困っているか、どんな作業に時間がかかっているか——現場の声を反映した仕組みは、自然と使われる仕組みになります。
属人化を防ぐ仕組み
中小企業でよくある課題が、「特定の人しかAIモデルのことがわからない」という属人化です。
MLOpsの仕組みを作る際は、以下の点を意識しましょう。
- ドキュメントを残す:なぜその設定にしたのか、どういう意図があるのかを記録
- 誰でも再現できる手順を作る:特定の人がいなくても、モデルを再学習・デプロイできる状態にする
- ナレッジを共有する:定期的に情報共有の場を設ける
ITに詳しい人材がいない場合の進め方
「うちにはAIやITに詳しい人材がいない」という企業も多いでしょう。しかし、専門家がいないからMLOpsができない、ということはありません。
学習から始める
今は、オンライン学習サービスや書籍、YouTubeなどで、MLOpsの基礎を学べる環境が整っています。社内の興味がある人材に学習の機会を提供し、少しずつ知識を蓄積していきましょう。
既存のテンプレートや事例を活用する
ゼロから仕組みを作るのは大変ですが、すでに公開されているテンプレートや事例を参考にすることで、ハードルは大きく下がります。多くのMLOpsツールには、サンプルコードやチュートリアルが用意されています。
シンプルな構成から始める
複雑な仕組みは、管理も運用も大変です。最初は最小限の機能だけを実装し、慣れてきたら少しずつ機能を追加していく方が失敗は少なくなります。
外部パートナーとの協力も選択肢
すべてを自社で行う必要はありません。外部の専門家やパートナー企業と協力することで、よりスムーズにMLOpsを導入できます。
外部パートナーに頼るメリット
- 専門知識を活用できる:自社で一から学ぶより、経験豊富な専門家の知見を借りる方が早い
- 客観的な視点が得られる:社内では見えにくい課題や改善点を指摘してもらえる
- 導入後の定着までサポート:ツールを入れて終わりではなく、現場で使えるようになるまで伴走してもらえる
パートナー選びのポイント
- 中小企業の支援実績があるか
- 伴走型のサポートをしてくれるか
- 自社の文化や業務フローを理解しようとしてくれるか
「丸投げ」ではなく「協働」の姿勢で
外部パートナーに頼る場合も、すべてを丸投げするのではなく、一緒に作り上げる姿勢が大切です。自社の課題や要望をしっかり伝え、提案された内容を理解しようとし、導入後は自社でも運用できるようにノウハウを吸収する——この協働の姿勢があることで、導入後も自社で改善を続けられる体制が整います。
まとめ|MLOpsは「AIを現場で活かし続ける」ための仕組み
ここまで、MLOpsの基本から具体的な取り組み方まで見てきました。最後に、記事全体の要点をおさらいしましょう。
MLOpsのポイント
MLOpsとは
機械学習モデルを開発・運用・改善するための一連のプロセスと仕組みのこと。「AIを作って終わり」ではなく、現場で使い続け、価値を出し続けるための考え方です。
MLOpsが必要な理由
- モデルは時間とともに劣化する
- 開発と運用の分断を防ぎ、スムーズな連携を実現する
- 属人化を防ぎ、組織全体でAIを活用できる体制を作る
主なメリット
- 品質の向上:安定した性能のモデルを提供できる
- スピードの向上:新しいモデルを素早く本番環境に適用できる
- リスクの低減:問題が起きても迅速に対応・復旧できる
- コストの削減:無駄な試行錯誤を減らし、効率的に開発できる
中小企業が取り組む際のポイント
- いきなり完璧を目指さない:小さく始めて、成功体験を積み重ねる
- 自社に合った仕組みを作る:教科書通りではなく、現場の声を反映する
- 外部パートナーとの協力も検討:すべてを自社で抱え込まず、専門家の力を借りる
自社に合った形で、無理なく始めよう
MLOpsは、決して大企業だけのものではありません。むしろ、限られたリソースで最大の効果を出す必要がある中小企業にこそ、MLOpsの考え方が役立ちます。
大切なのは、「完璧な仕組み」を作ることではなく、「続けられる仕組み」を作ることです。
Excelでの実験記録から始めてもいい、一つのモデルだけ自動化してみるのもいい、外部の力を借りながら進めるのもいい——自社の状況に合った「ちょうどいい」形で、まずは一歩を踏み出すことが何より重要です。
AIを現場で活かし続けるために
「AIを導入したけど、うまく活用できていない」
「モデルの精度が落ちてきて、どう対応すればいいかわからない」
「属人化から脱却したいけど、何から始めればいいか迷っている」
もし、こうした課題を感じているなら、それはMLOpsに取り組む良いタイミングかもしれません。
Harmonic Societyは、中小企業の「ちょうどいいデジタル化」を支援する会社として、AI活用の計画づくりから実際に使えるようになるまで、伴走型でサポートしています。
- 自社の状況に合った現実的なMLOpsの仕組みづくり
- 現場で使える形でのAI導入・定着支援
- 「大きすぎず、小さすぎない」最適なソリューション
**まずはお気軽にご相談ください。**一緒に、あなたの会社に合った「AIを活かし続ける仕組み」を考えましょう。
AIは、導入して終わりではありません。現場で活かし続けてこそ、本当の価値が生まれます。その第一歩を、私たちと一緒に踏み出しませんか?